Persistence
I/O Devices¶
System Architecture¶
prototypical system architecture 如下图所示:
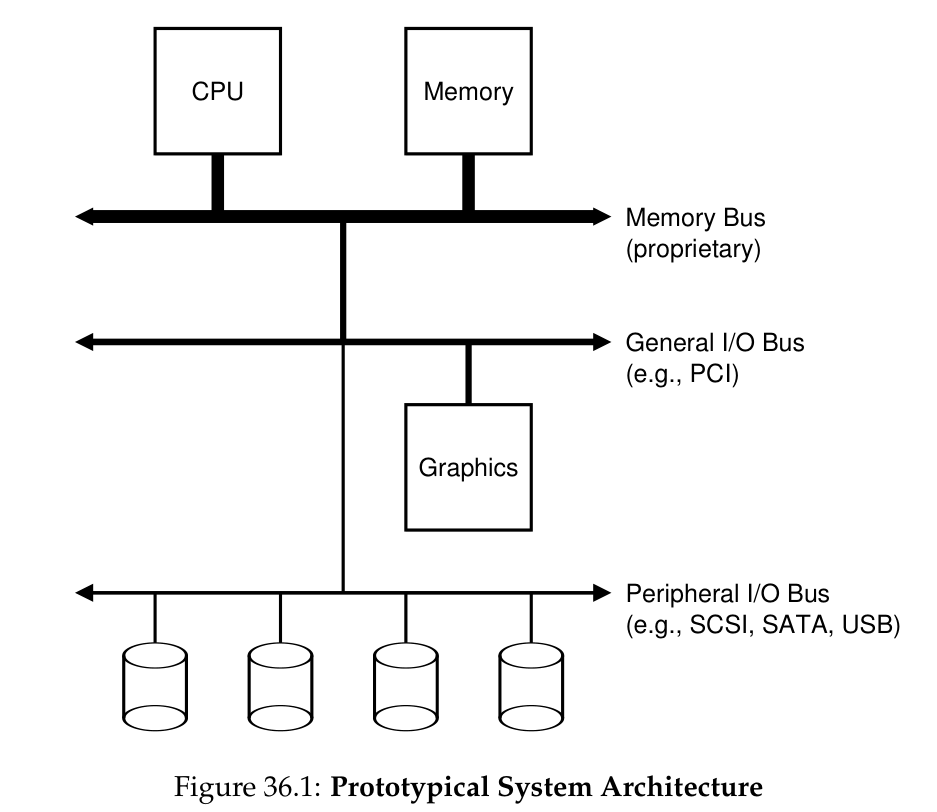
分三级的原因是 bus 速度越快就越短、越 costly,类似于 Cache,bus 也是从上往下越来越慢、越来越长、越来越便宜。
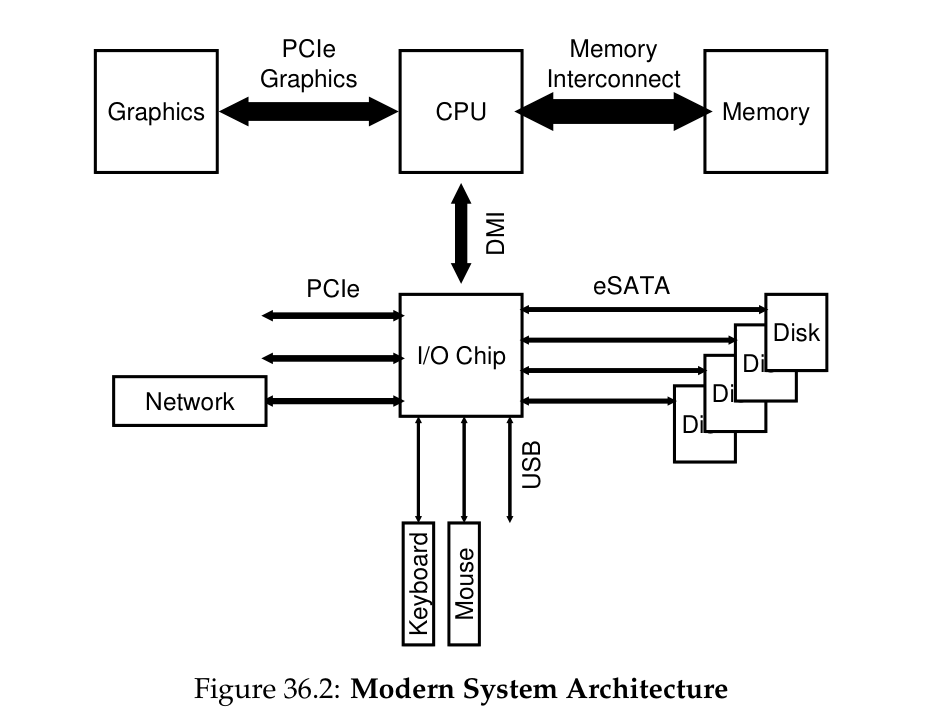
在 modern system 中则主要使用如下图的架构:
A Canonical Device¶
一个 canonical device 需要给 system 提供 interface 来允许 system software 对其进行操作,它还需要有 internal structure 负责提供 implementation abstraction.

The Canonical Protocol¶
system software 遵循一定的 protocol 通过 device 提供的 interface 与其进行交互。interface 通常包括 status register、command register、data register,而相应的 protocol 可能包含 4 步:
While (STATUS == BUSY);等待直到 device 不再 busy,OS 通过重复读取 status register 来等待 device 可以接受 command 的过程被称为 polling- 将 data 写入
DATAregister,如果 data movement 这一步包含了 main CPU,就称这个 I/O 为 programmed I/O (PIO) - 将 command 写入
COMMANDregister While (STATUS == BUSY);等待 device 完成命令
Optimization¶
polling 会降低 performance,一个解决办法是 interrupt. 具体而言,需要进行 data movement 时,OS 发起 request 将 calling process 移入 sleep 状态并 context switch 到另一个 task,允许 I/O 与 computation 的 overlap, 当 device 完成操作后就会提出 hardware interrupt, 让 CPU jump 到 OS 的 interrupt service routine (ISR) 或者说 interrupt handler, 接着就会唤醒正在等待 I/O 的 process.
interrupt 并不一定总是最好的方法,当 device 很快时更耗时的就变成了 interrupt 带来的 context switch 等操作。若 device 的速度未知或者时快时慢,可以使用 hybrid approach, 即先 poll 一会儿,若 device 还未完成操作就 interrupt. interrupt 另一个缺点是在 network 下,给每个 incoming packet 一个 interrupt,若 stream 很大时会导致 OS 忙着处理 interrupt 而没有时间允许对应的 user-level process 处理 packets,接收不到 packet 的 process 重复请求 packet,这样就会产生 livelock.
另一个基于 interrupt 的优化是 coalescing, 即 device 完成操作后先不急于发出 interrupt,而是等待一段时间再发出一个 interrupt,等待时间内新的 I/O request 的操作也完成的话会将这些多个的 interrupts 并入到实际发出的单个的 interrupt 中。当然,等待太久会提高 request 的 latency.
另外,第 2 步让 CPU 来完成 data movement 也是对 CPU 资源的浪费,解决方案是使用 Direct Memory Access (DMA) engine 来 move data: OS 告诉 DMA engine data 在 memory 中的位置、需要多少 data、目的 device 是谁,接着 OS 处理其他任务直到 DMA engine 完成后发起 interrupt 告知 OS.
Methods Of Device Interaction¶
device communication 主要有两种方式,一种是通过 I/O instruction 由 OS 作为与 device 的直接交互对象,这样的 instruction 通常是 privileged.
另一种方式是将 device 注册为 memory 中的某一地址,由 OS 对相应 register 的地址发起 load/store 指令,然后 hardware 将指令 route 到实际的 device,这种方法被称为 memory-mapped I/O.
Fitting Into The OS: The Device Driver¶
不同 device 对于某一个命令在内部需要具体进行的操作不同,为了尽可能 keep general,device 内部使用被称为 device driver 的 software 完成操作,而 OS 需要知道的只是 device driver 封装了什么样的操作,这个方法也就是经典的 abstraction.
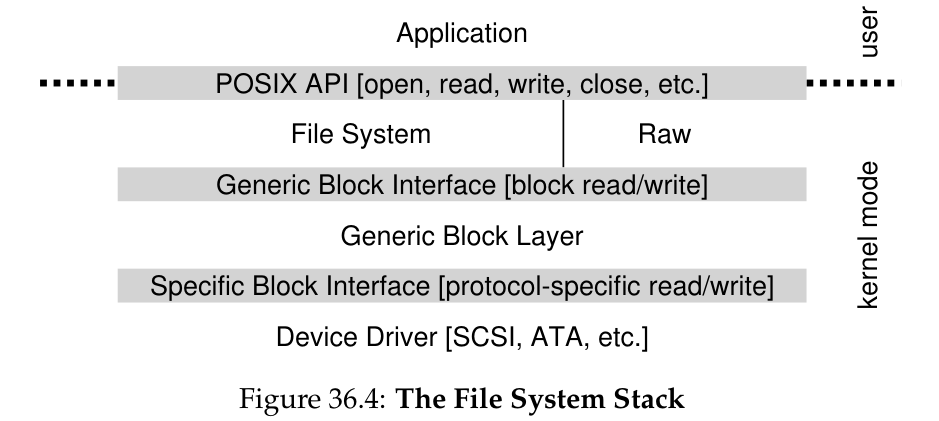
以 file system 为例,file system 只需通过 generic block interface 发起 block read/write, 然后由每个 block 的 device drive 完成 protocol-specifiv read/write, 另外还提供了 raw interface 允许特定的 application(例如 file-system checker、disk defragmentation tool)可以直接对 blocks 进行读写而不需要使用 file abstraction. 另外,encapsulation 可能导致 device 的一些 special capabilities go unused.
有意思的是,device drivers 相关代码占据了 kernel code 的大部分,而这部分代码一般由非 full-time kernel developers 撰写,往往容易产生很多 bug 并造成 kernel crash.
Hard Disk Drives¶
一个 modern disk drive 由大量的 sectors(即 512-byte blocks)组成,包含 \(n\) 个 sectors 的 drive 的 address space 为 \(0 \sim n-1\), 即每个 sector 的序号,在 OS 视角中,drive 被看作长度为 \(n\) 的 sector array.
每个 sector 的读写操作是 atomic 的,当一次性对多个 sector 进行写入且发生断电时,只有一部分 sector 的任务可以完成,这被称为 torn write. 相邻访问的 blocks 距离越近访问速度就越快。
Basic Geometry¶
disk 的 data 被储存在名为 platter 的 circular hard surface 上,一个 disk 可以有多个 platter,每个 platter 有 2 个 surface, platter 都被绑定在名为 spindle 的圆心周围,每一个由编码了 data 的 sectors 构成、以 spindle 为圆心的圆被称为 track, 它可以被 spindle 转动,一个 surface 由很多个 track 组成,drive 使用 disk head 对单个 sector 进行读写,它被连在 disk arm 上来进行移动。
spindle 转动的速率用 rotations per minute (RPM) 来衡量,在相应 track 上的 disk head 等待 spindle 转动到正确的 sector 的时间就是 rotational delay,半径为 \(R\) 的 track 的平均 rotational delay 大约为 \(\frac{R}{2}\).
如果有多个 track 则还会存在 seek time, 即 disk head 移动到正确的 track 上需要的时间,在这个过程中会经过 acceleration、coasting、deceleration 三个阶段(经典梯形 \(v-t\) 图),同时 spindle 会保持转动。
最后从 surface 对 data 进行读写还会存在 transfer time. 完整过程为:先 seek,再等待 rotational delay,最后 transfer.
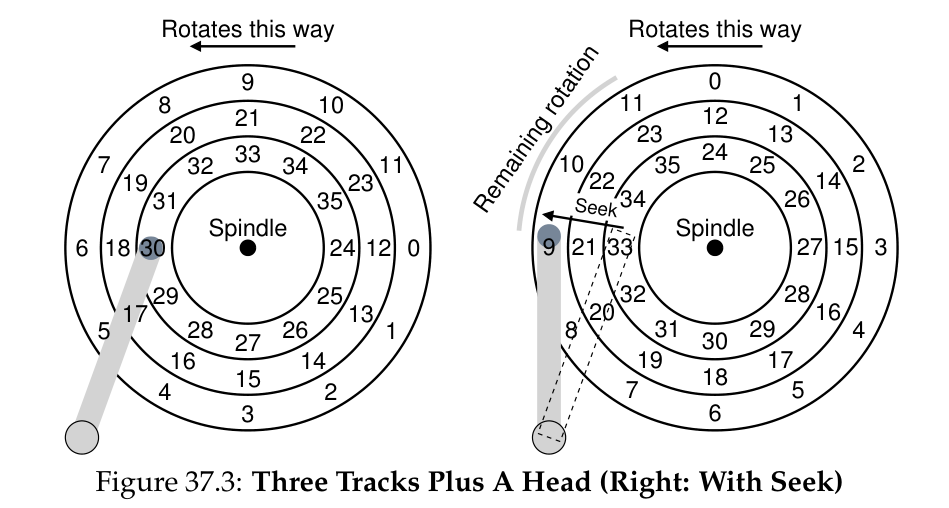
由于在 track 间移动的同时也会存在 rotation,为了方便跨 track 的 sequential reads,很多 drive 会应用某些 track skew,即将 outer track 最后一个 sector 的下一个 sector(位于 inner track)向转动方向偏移一些距离,使得 disk head 从 outer track 移动到 inner track 的过程中访问的 sector 是连续的。
因为 outer track 的半径较大,一般会存放更多的 sectors,这样的 drive 被称为 multi-zoned disk drive.
modern disk drive 也会有相应的 cache (也称为 track buffer), 这就有会产生 write back caching (也称为 immediate reporting) 和 write through caching 的不同选择。
I/O Time¶
I/O time 由 seek time、rotational delay 和 transfer time 组成:
I/O 的速率定义如下:
drive 的 workload 可以简单分为 random workload 和 sequential workload 两种:
- random workload: issue small reads to random locations
- 计算 \(R_{I / O}\) 时一般按照单次少量数据(例如 4KB),单次 seek time,平均一次 rotational delay(即 rotational delay / 2)和相应的 transfer time (一般较于前两者很小可以忽略) 计算
- sequential workload: reads a large number of sectors consecutively
- 计算 \(R_{I / O}\) 时按照单次大量数据(例如 100MB),单次 seek time、rotational delay 和相应的 transfer time(此时一般较大不可忽略)计算
Disk Scheduling¶
不同于进程调度,disk scheduler 往往能对“job”大小有较好的估计,因此会尽量采取 principle of SJF (shortest job first).
一种方式是将 I/O requests 按照所在 track 离当前 disk head 的距离大小排序后选择最近的 request 完成,这被称为 shortest-seek-time-first (SSTF) (或是 shortest-seek-first (SSF)), 对于不知道 drive geometry 的 OS,可以改为 nearest-block-first (NBF). 但是上述方法存在 starvation,即 disk head 总是在一小块区域来回移动而忽略较远区域的 request.
SCAN 算法则规定 disk head 只在一个方向上移动(将 disk 的单次遍历称为 sweep),完成所有路上的 requests,到达当前方向最后的 track 才掉转将原先错过的 requests 加入处理队列,SCAN 的方式与 elevator 的调度方式相同,它解决了 starvation 的问题,但是会存在 middle track 占便宜的情况。
F-SCAN 是 SCAN 的一个变种,它在 sweep 的过程中不处理新到来的 requests,而是将其加入队列在下一遍 sweep 时再处理,通过推迟晚到来的 requests 来避免较远处的 requests starve.
Circular SCAN (C-SCAN) 则规定只有当 disk head 朝 outer-to-inner 方向移动时才处理 requests,返回则直接快速移动到 outermost track,将 sweep 方向缩小到一个来避免 SCAN 算法中 middle track 占便宜的情况。
SCAN 算法及其变种都并没有采取 principle of SJF 而是直接忽略了 rotation 的存在,因此并不是最好的调度算法。
那么最好的答案是什么呢?
It depends.
shortes positioning time first (SPTF) 算法在 seek time 明显高于 rotational delay 时采取 SSTF 算法,否则当 seek 只比 rotation 快一点时就优先处理 rotation 方向上距离 disk head 较近的 request. modern drive 的 seek 和 rotation 开销一般相差不多,因此 SPTF 可以提高 performance. 而对于不清楚 track boundaries 与 disk head 位置的 OS 来说 SPTF 难以实现,因此一般做法是 OS 按照自己的调度算法选择一些 requests 交给 disk,然后由 disk 内部自行实现 SPTF.
除了 delay 和 OS 对 drive 内部的不知情的问题之外,scheduler 还需要完成 I/O merging 将访问相邻或相同 sectors 的 requests 合并为一个大的 request 来减小 overheads. 另外 scheduler 还可以选择是否在收到 request 时就立即想 disk 发出 issue,立即 issue 的方法被称为 work-conserving, 它保证了存在 request 时 disk 不会进入 idle 状态;等待一段时间后再进行 issue (anticipatory disk scheduling)的方法则是 non-work-conserving, 它可以提高整体的效率。
Interlude: Files and Directories¶
本节介绍 persistence storage (如 hard disk drive、solid-state storage device) 的 virtualization 相关问题。
Files And Directories¶
storage 的 virtualization 有两个 key abstraction: file 和 directory.
file 是一个 linear array of bytes, 每个 file 有一个 low-level name 便于识别管理,它通常叫作 inode number (i-number).
directory 同样也有一个 low-level name (inode number), 它的内容与 file 不同,包含的是由 (user-readable name, low-level name) 二元组组成的 list. 通过在 directory 里面放置 directory 可以构建一个 directory tree (或称为 directory hierarchy).
directory hierarchy 以一个 root directory 作为根节点,使用一些 separator 给后继的 sub-directories 命名,从 root directory 开始的完整名称被称为 absolute pathname.
file 还会存在 . 作为 separator,. 后面的部分用来表示 file 的 type.
The File System Interface¶
- Creating Files:
int open(const char* pathname, int flags, .../* mode_t mode */);- 返回 file descriptor, 为每个 process 维护的 open files array 中的下标,其中 0、1、2 一般分别被 standard input、standard output、standard error 占用
- 对 file 进行一些操作需要使用 file descriptor, 可以将其看作 capability;
- 也可以将其看作 file object 的 pointer.
flags指定 access modes, 第 3 个 parameter 则指明 permissions
- 返回 file descriptor, 为每个 process 维护的 open files array 中的下标,其中 0、1、2 一般分别被 standard input、standard output、standard error 占用
- Reading Files:
ssize_t read(int fd, void buf[.count], size_t count);buf[.count]为存放 reading result 的地方,count则是要读取的 byte 数目- 返回值为实际读取的 byte 数目
- Writing Files:
ssize_t read(int fd, void buf[.count], size_t count);
xv6 的 file 结构体如下:
每个 file 会维护一个 offset 值 off 来表示下一个要读/写的位置,当 open 一个 file 时会将其初始化为 0,使用 read() 和 write() 会 implicitly 更新 off 完成 sequentially read/write, lseek() 可以 explicitly 更新 off,再结合 read()/write() 来做到非 sequentially read/write:
其中 offset 为希望 off 更新的值,whence 则具体指定 seek 的执行方式:
whence = SEEK_SET:off = offset;whence = SEEK_CUR:off += offset;whence = SEEK_END:off = size(fildes) + offset.
由于 storage 是所有 process 之间共享,因此需要 OS 来维护 opened files, 它们形成的 file structures 有时也被称为 open file table. xv6 系统中将其看作一个 array,并使用单个 lock 来保护整个 table.
如果对同一个 file 进行多次 open(), 每一次会分到不同的 file descriptor, 对应 open file table 中的不同 entry,因此它们的 off 等值并不共通。
若使用 fork() 创建子进程,那么父子进程之间的共享的 file descriptor 在 open file table 中对应的 entry 也是相同的,此时就会用到 reference count: 当 file table entry 被共享时就会增加它的 reference count ref, 只有当所有使用了它的 process 都 close file 后才会实际 remove 整个 entry.
如果希望创建一个新的 file descriptor 对已有的 open file 进行操作可以使用 dup(), 它常用于 UNIX shell 程序及类似 out redirection 的操作中。
由于存在 disk scheduling 等优化 performance 的问题,call write() 并不会立即将 data 写入 storage 而是在 memory 中 buffer 一段时间后再进行写入,若在实际写入 data 之前出现 machine crash 则会失去这部分 data. 尽管这个概率相当小,但是对于一些数据保存要求高的应用(例如 DBMS)就需要提供强制立即写入 storage 的手段。UNIX 提供的 API 则是 fsync(int fd), 它会强制将所有 dirty data 写入 disk.
值得注意的是,对含有新创建的文件 foo 使用 write() 后进行 fsync() 可能还需要对它的上级目录进行 fsync(), 因为可能出现 foo 所在 directory 存在 dirty data 而先写入 foo 的 data 后更新 directory 的 data 则会使 directory 丢失 foo 的 metadata.
rename(char *old, char *new) 可以 rename file, 为了避免 system crashes 对 rename file 造成奇怪的错误,它通常被实现为 atomic call. file editor 常利用其 atomicity 来实现对 file 的 update,例如:
int fd = open("foo.txt.tmp", O_WRONGLY|O_CREAT|O_TRUNC, S_IRUSR|S_IWUSR);
write(fd, buffer, size);
fsync(fd);
close(fd);
rename("foo.txt.tmp", "foo.txt");
除了 file access 以外,file system 还会维护它保存的 file 的一些信息,即 file metadata, 可以使用 stat() 或 fstat() 进行查看,而 file system 维护 metadata 所使用的 structure 则正是 inode. 不同于 file, directory 的 format 是 file system metadata, 它只能被间接更新,例如在 directory 下创建 file、directory 等。
创建 directory 的 system call 为 mkdir(), 新建立的 directory 被视为“empty”,它只有 . 和 .. 两个 entry 分别指向它自己和它的 parent.
reading directories 相关 calls 为 opendir()、readdir() 和 closedir(), 一般使用一个简单的 loop 来依次读取一个 directory entry, 它的结构体定义如下:
struct dirent {
char d_name[256]; // filename
ino_t d_ino; // inode number
off_t d_off; // offset to the next dirent
unsigned short d_reclen; // length of this record
unsigned char d_type; // type of file
};
删除 directory 的 call 为 rmdir(), 为防止误删大量 data,rmdir() 要求删除的 directory 必须为空。
创建新的 directory entry 除了创建新的 file/directory (新的 inode),也可以通过 link() 来实现。link() 的 2 个 arguments 分别为 old pathname 和 new pathname, 允许为同一个 file (inode) 创建一个新的 filename(增加 reference count),当使用 rm 删除其中一个 filename 时并不会实际删除 file,而是 call unlink() 取消这个 filename 到 inode 的 “link”(减少 reference count),仍然可以通过另一个 filename 访问该 file, 只有当 reference count 减少到 0 时才会实际删除,这样的 link 被称为 hard link.
hard link 存在一些限制,例如不能 link directory(防止产生 reference cycle)、不能 link 到别的 disk partition 上的 file(inode 只在一个 file system 中是 unique 的),而 symbolic link 或称之为 soft link 则解决了这些限制。
soft link 的创建可以用 ln -s 实现,它属于另一种 file type:symbolic link. 它的 data 仅仅是 linked-to file 的 filename,建立与删除 soft link 并不影响原始 file, 但是删除原始 file 而没有删除 soft link 时就可能出现 dangling reference.
Permission Bits And Access Control Lists¶
UNIX file system 使用 permission bits 来给不同的 users、processes 提供不同程度的 sharing. 使用 ls -l 命令可以查看 file/directory 的 permission bits:
-rw-r--r-- 为需要关注的地方,第一个字符表示文件的类型:- 表示 regular file, d 为 directory, l 则是 symbolic link. 后面 9 个字符的则是 permission bits, 分别代表 file 的 owner、某个 group 中的用户和其他人(即 other)能对 file 做的事情,r 表示可读,w 表示可写,x 表示可执行,permission bits 可以用 chmod 命令更改(即修改 file mode)。
对于 directories,execute bit 表示的是是否允许 user(或 group、everyone)使用 cd 进入 directory 等操作,配合 write bit 可以表示是否可以在 directory 内创建 file.
一些其他的 file system 会采用不同的方式进行 access control,例如 AFS 采用的则是 access control list (ACL), 它可以使用 fs listacl 命令查看文件的 ACL.
Making And Mounting A File System¶
要装配很多不同的 file system 为一个 full directory tree 需要完成两步:先制作 file systems,然后将它们 mount 上去。
mkfs 命令可以制作一个 file system:给定一个 device(例如一个 disk partition, e.g., /dev/sda1)和一个 file system type(e.g. ext3),它会在相应的 disk partition 上写入一个只有 root directory 的 empty file system.
而 mount() 则将一个现有的 directory 作为 target mount point, 然后将一个 new file system paste 到 mount point 的 directory tree 上,从而可以允许在 uniform file-system tree 中 access 新创建的 file system.
File System Implementation¶
本节以 vsfs (Very Simple File System) 为例讲解 file system implementation.
构建一个 file system 主要需要考虑两个方面:
- data structure: file system 使用什么类型的 on-disk structure 来储存 data 与 metadata
- access methods: 即 file system 如何允许 process 使用 calls 来访问其内部结构
Overall Organization¶
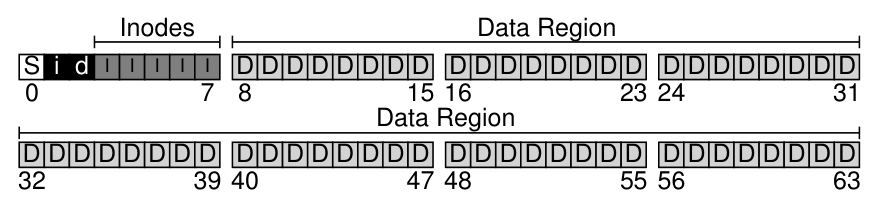
file system 首先将 disk 分成一些 blocks, 每个 block size 可能不唯一,简单起见,vsfs 仅使用 4KB 作为 block size.
file system 跟踪 file 需要维护的 information 称为 metadata,一般用 inode (short for index node) 结构体进行存储。
disk 中存储 user data 的部分称为 data region, 另外还需要存储 inode 的空间,这部分被称为 inode table, 以 array 的形式存储。
file system 还使用 allocation structures 来 track inodes 和 data blocks 被 free/allocated 的情况,这样的 structure 可以是 free list, 即使用 list 存储指向每一个 free block 的指针,vsfs 采用的则是 bitmap 的结构,一个 data bitmap 来存储 data region 的信息,一个 inode bitmap 存储 inode table 的信息,bitmap 的每一个 bit 的 0/1 值表示该 bit 对应位置的 object/block 是 free/in-use.
file system 还需要使用一个 block 来存储 file system 的信息,例如它包含了 inodes 及 data blocks 的数量、inode table 的起始位置,以及一个 magic number 表示 file system 的类型,这个 block 即是 superblock.
当 mount 一个 file system 时,OS 会先读取 superblock 来初始化一些 parameters,然后再将这个 volume attach 到 file-system tree 上。
File Organization: The Inode¶
每个 inode 会有一个 i-number,它也是 file 的 low-level name,利用下列公式可以直接计算出该 inode 在 inode table 上的 offset:
file system 需要向 disk drive 发起 issue 才能 fetch 这个 block,而 disk drive 使用的单位是 sector(一般为 512 bytes),因此还需要计算该 block 所在 sector 的位置:
inode 内部存储的一个重要信息是该 file 对应的 data blocks 的位置,一个简单的存储方法是用 direct pointers 直接存储每个 data block 的位置,但是当文件非常大时,一个 block 可能不够存储 direct pointers, 因此可以引入 indirect pointer, 它指向用于存储 pointers 的 block 的位置,double indirect pointer.
由于大部分 file 都是较小的,因此一般 inode block 会存储小量 direct pointers 和一个(或者更多)indirect pointer 指向 indirect block.
Directory Organization¶
在很多 file system 中,directory 的 organization 只是简单地由一个存储它内部的 file & directory 的 (entry name, inode number) pair 的 list 组成,额外地,这里的 entry name 都还需要额外存储一些信息,例如一个可能的 directory dir 的 on-disk data 如下:
| inum | reclen | strlen | name |
|---|---|---|---|
| 5 | 12 | 2 | . |
| 2 | 12 | 3 | .. |
| 12 | 12 | 4 | foo |
| 13 | 12 | 4 | bar |
| 24 | 36 | 28 | foobar_is_a_pretty_longname |
其中,strlen 为 name 的长度(包括 \0),reclen 则是 name 和这个 entry 剩余的空间的总长度,当删除一个 file 时会在 directory 中间留下 empty space,此时若有新的 entry 则可以 reuse 这个 empty space 并且留下新的空隙,这既是 reclen 存在的原因之一。
file system 一般将 directory 当作一种特殊的 file 来处理,因此 directory 同样也有 inode,被存储在 inode table 中,上述 data 同样被存储在 data region 中。
Free Space Management¶
file system 需要 track inodes 与 data blocks 的 free 与否的信息便存储新的 file/directory 信息,因此需要 free space management.
以 vsfs 为例,当创建一个新 file,首先搜索 inode bitmap 找到一个 free inode,然后将其分配给这个新的 file,这就需要修改对应的 inode bit 为 1,最后再更新 data bitmap.
分配 data blocks 时也存在一些策略,例如 ext2 和 ext3 会分配一个 free block 的序列给新的 file 从而保证新 file 在 disk 上是连续存放的,继而优化 performance,这样的策略被称为 pre-allocation policy.
Access Paths: Reading and Writing¶
当使用 open("/foo/bar", O_RDONLY) call 时,file system 首先需要找到 bar 的 inode 来得到它的一些基本信息(例如 permissions information、file size 等),这要求 file system traverse the pathname 来定位 inode:
- 从 file system 的 root 开始,即 root directory
/.- root directory 的 i-number 是 well known 的,一般为 2, 于是 FS 先读取 i-number 为 2 的 block(第一个 inode block)
- 然后读取它的 pointers to data blocks
- 再用这些 on-disk pointers 读取 directory 的 data blocks,寻找
name为foo的 entry - 寻找到
foo的 entry 后也就得到了它的 inode number
- 接着递归 traverse the pathname 直到找到
bar的 inode
Note
open() 需要的 I/O 量与 pathname 成正比,每一个途径的 directory 不仅需要读取它的 inode,还需要读取它的 data.
open() 的最后一步则是将 bar 的 inode 读入 memory,FS 会接着做一个 final permissions check,再在 per-process open-file table 中分配 file descriptor,最后返回 file descriptor 给 user.
read() 则会从 memory 中的 inode 找到 file 的 data blocks 的 location,然后从 disk 中读取第一个 block 并更新 inode 存储的 last-accessed time 以及更新 in-memory open file table 中的 file offset.
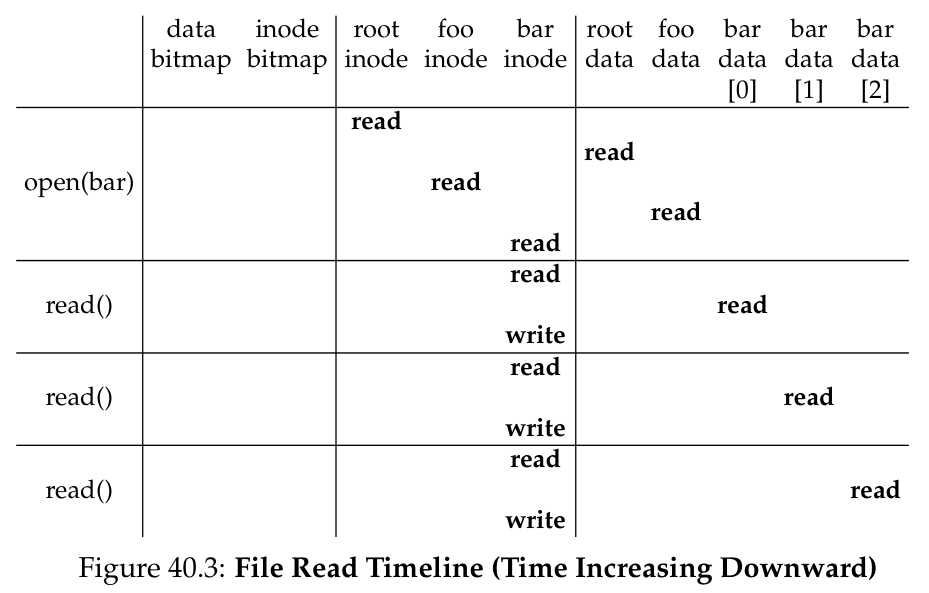
而 close() 则只需要 FS deallocate file descriptor,不需要进行 I/O.
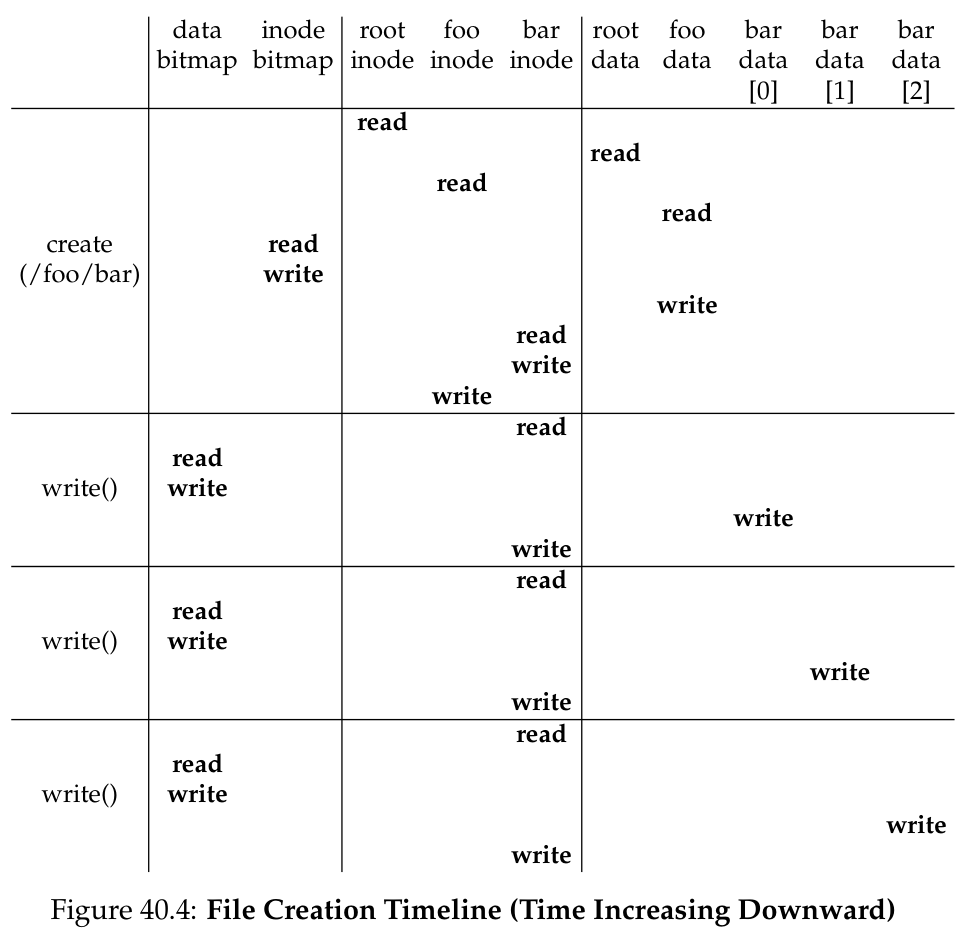
与 reading 不同,writing 可能需要 allocate block. file 的每一个 write 操作会产生 5 个 I/O:
- read the data bitmap
- write the bitmap(标记 newly-allocated block 为被占用)
- read the inode
- write the inode(更新 file 在 disk 上存储 data 的状态)
- write the actual block itself
file creation 需要 FS 分配 inode、在包含需要创建的 file 的 directory 中分配空间,需要的 I/O 量非常大:
- read the inode bitmap(寻找 free inode)
- write the inode bitmap(分配 inode)
- write the new inode itself(初始化 inode)
- write the data of the directory (link the high-level name to its inode number)
- read & write the directory inode(更新)
- 若 directory 已有的空间不够分配,则还会需要 additional I/Os
Caching and Buffering¶
为了提高 performance,大部分 FS 会使用 system memory (DRAM) 来 cache 重要的 blocks(例如 cache 常用的 directory 的 data blocks 方便索引).
早期的 FS 使用 fixed-size cache 来存储 popular blocks,类似 LRU 的策略可以用来决定 cache 中需要存储的 blocks.
由于 FS 在不同时间需要的 disk 访问量不同,static partitioning of mamory 在 file I/O 的需求量较少时则是一种浪费,于是现代的 FS 通常使用 dynamic partitioning 方法,并且将 virtual memory pages 与 file system pages 整合进一个 unified page cache, 使得 memory 的分配更灵活。
write 操作的 cache 与 read cache 的作用不同,write buffering 还有下列好处:
- 通过延迟 writes,FS 可以 batch 多个 updates 到一个 smaller set of I/Os
- 另外还方便 schedule subsequent I/Os 来提高 performance
因此,现代的 FS 通常将 writes buffer 在 memory 中持续 5s 到 30s, 相应的 tradeoff 则是若 system 在这段时间 crash 了就会丢失这些 updates.
一些不能接受数据丢失的 applications(例如 databases)则会 call fsync() 来使用 direct I/O interface 避开 cache,或者使用 raw disk interface 避开 FS.